

Hugging Face Transformers in Action – An introductory guide.
The fast-paced development of Transformers has brought in a new wave of powerful tools for NLP – Natural Language Processing.
Such models are relatively large and quite expensive to train – thus, pre-defined versions are shared and leveraged by practitioners and researchers. Hugging Face provides a variety of pre=trained transformers as open source libraries, and you can easily incorporate these with only one line of code.
Hugging Face
Before we start on the deeper learning curve, you should clearly understand the use cases, purpose, and applications. Hugging Face has many transformers and models that are specific to particular tasks. The platform offers an easy gateway for searching models, and you can easily filter out the list by tweaking the filters.
What is a Transformers Pipeline?
The transformers pipelines are an abstraction for complex code behind the transformers library – it is easy to use the predefined models for inference. Providing the easiest pipeline functions for a multitude of tasks.
For ML and deep learning experiments, we have to pre-process data, train the model, and write an inference script, in contrast to the Pipeline functions, where we need to import it and pass the raw data. Pipeline shall pre-process the data in the backend, including tokenization and padding along with all the relevant processing steps for algorithm input – and return output with only a call to it.
What is a pipeline in hugging Face?
Hugging Face pipelines are objects that abstract complex code from the library, offering a simple API that can be dedicated to many tasks, including yet not limited to;
- Masked Language Modeling
- Named Entity Recognition
- Feature Extraction
- Sentiment Analysis
- Question Answering
Why go for a Machine Learning Pipeline?
It is recommended, and beneficial to look at the stages multiple data science teams go through to understand the ML pipeline’s advantages clearly. Implementation of the first ML model tends to be problem-oriented, and the data scientists emphasize constructing a model to crack a single business problem at a time – for instance, classifying images.
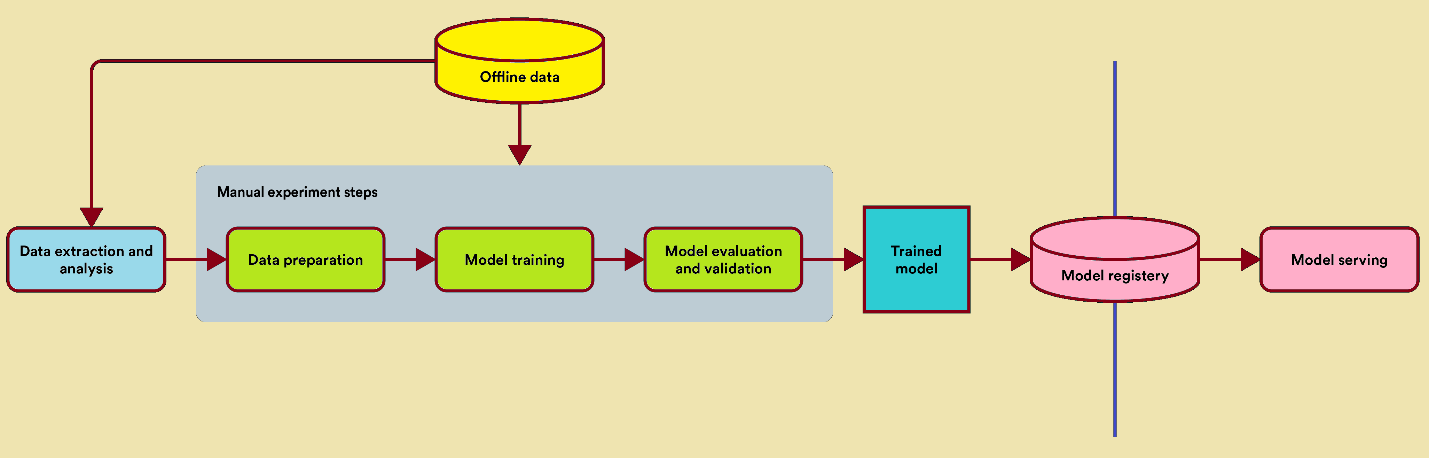
Manual Cycle
Teams normally begin with manual workflow, where no actual infrastructure exists.
The data collection, model training, data cleaning, and evaluation are probable to be written in a single notebook. That notebook is run locally for producing a model, which is then handed over to an engineer obliged to turn it into an API endpoint.
For this workflow, the model is the product.
Automated Pipeline
As teams move on from a stage where they need to occasionally update a single model to having to regularly update models in production – the pipeline method becomes dominant.
In the automated workflow, you do not build or maintain a model but develop a pipeline.
Here, the pipeline is the product.
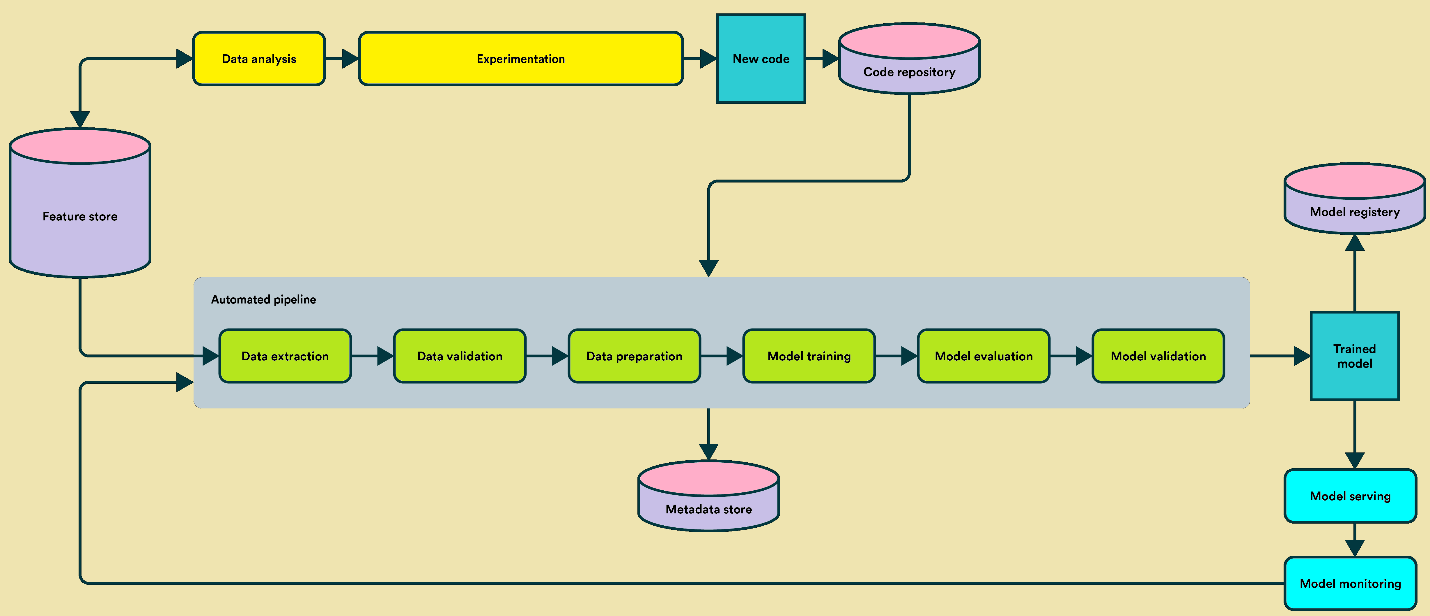
The pipelines condense the overall process of every NLP process;
- Tokenization
Tokenization splits initial input to multiple sub-entities with properties such as tokens.
- Inference
Here each token is mapped into a more clear and more meaningful representation.
- Decoding
Use the above meaningful representation for generating or/and extracting the final output for the primary task.
Are pipelines Transformers or an estimator?
A pipeline is an Estimator, and after a pipeline’s method runs, it produces a Pipeline-Model; this model is a Transformer.
What are Transformers?
Transformers in NLP is a novel architecture aiming to solve sequence-to-sequence tasks while also handling the long-ranging dependencies with simplicity.
Hugging Face is an NLP-focused platform that offers a structured pipeline with which users can easily move from one framework to another for the ML model training and evaluation.
Transformers as a whole package contains more than 30 pre-defined models and 100 languages, with 8 major architectures for the NLU (Natural Language Understanding) and NLG (Natural Language Generation), including;
- BERT
- GPT
- GPT-2
- Transformer-XL
- XLNet
- XLM
- RoBERTa
- DistilBERT
Transformers library no longer needs PyTorch to load models while being capable of training SOTA models in under 3 lines of code and can also pre-process a dataset with less than 10 lines of code. Plus, sharing models also minimizes the computation costs and, by extension – carbon emissions.
Hugging Face Transformers in Action
Initially, the transformers were introduced as novel architecture for language translation. They are still mostly used for natural language processing.
For instance:
- Text Classifications
- Sentiment Analysis – examining if the text is positive or negative.
- Document Sorting – in which folder this email or document should go? Text generation:
- Text Generation
For writing a blog post from scratch on what to do for a summer garden. This can be done with GPT3.
- Named-Entity Recognition
Extraction of vital entities from the text, like the persons’ names, dates, location or prices, etc
- Parts-of-Speech Tagging
Proper tagging of the text based on their grammatical role: adjectives, nouns or verbs, etc
- Translation
And, of course, a full-fledged proper translation.
You can use the pre-trained transformer models to perform these tasks efficiently.
Why Hugging Face?
The Hugging Face has positioned itself as a massive open-sources platform and, most importantly, a community.
It has quickly become an attractive hub for pre-trained deep learning and machine learning models, mainly targeting NLP tasks. The core mode of operation for NLP centers on the use of Transformers. Stay tuned to Qwak for more community helping guidelines and platform engagement.